The platform gets better every time it operates.
Models improve in the field, on live operational data, and only encrypted weight updates ever leave the device, never the raw data. Scaleout Edge runs the full model lifecycle at the edge: federated training, versioned deployment, resilient operations, and fleet-wide observability.
Trusted by leading organisations
A fundamental constraint. Not a tooling problem.
Standard ML assumes data can be centralised, networks are reliable, and models stay accurate once deployed. At the edge, none of those assumptions hold.
The data can't move.
Classification boundaries, privacy law, and bandwidth make centralisation non-compliant or impractical. This disqualifies most ML architectures before they start.
The network can't be trusted.
Contested environments, remote sites, and mobile fleets operate where connectivity is intermittent or denied. Any system that requires a live cloud link is a single point of failure.
One model doesn't fit the fleet.
Conditions at the edge change faster than centralised retraining cycles can follow. A model trained on averaged data washes out the local patterns that matter most.
The fleet is a black box.
No central record of which model version ran where, what data shaped it, or when it last updated. In regulated or safety-critical systems that's not an ops problem: it's an accountability void.
Four dimensions of operational advantage.
Speed, accuracy, reach, and resilience. Each is a direct consequence of training where the data already is, instead of shipping it back to a central model.
A new pattern at one node becomes a fleet-wide capability in the same operational window.
- 1 Observe: a new failure mode, object class, or acoustic signature shows up at one node
- 2 Confirm & retrain: an operator confirms through a simple interface; the model retrains on-site
- 3 Redeploy: across the fleet within the same window, not the next release cycle
Active learning auto-selects the high-value data; the node retrains locally and verifies before the model is promoted.
Trained on that environment, that site, that operating condition.
- Real local data: a North Sea platform learns from North Sea conditions, improving as the deployment runs
- Not a central set that only approximates it
Each node adapts to its local distribution; the federation reconciles those gains into a stronger shared model without raw data moving.
What one node learns, every node benefits from.
- One site learns: a new pattern is identified at one site
- Every node benefits: the model improves across the entire fleet, no raw data leaving any site
- Collective intelligence that compounds with every deployment, which a centralised loop cannot deliver
Only encrypted weight updates are aggregated across the fleet, model updates orders of magnitude smaller than the raw data, which stays on the device.
No persistent uplink required. A disconnected node keeps learning.
- Connected: full federated training, staging, and observability
- Intermittent: operates autonomously, queues updates for next sync
- Disconnected: runs inference, captures data, trains locally. Nothing is lost.
Offline-first by design; compact weight updates sync on reconnect, with minimal bandwidth across constrained, intermittent, or contested links.
The model goes to the data. Not the other way around.
Four principles, each a direct response to the constraints that make conventional ML fail at the edge.
Continuous training on live data
Edge nodes train directly on local data as conditions change. No centralised retraining cycles. The platform improves from what it observes, not from what can be sent back.
Only encrypted updates leave the device
Raw data is architecturally confined to the edge. Only model weight adjustments travel, orders of magnitude smaller than the raw data, and they are hardened against inference with secure aggregation and privacy auditing. Sovereignty is enforced by system design, not access-control policy.
Designed for denied connectivity
Nodes train independently and sync when connectivity allows. A node that loses signal continues learning. When it reconnects, its updates merge automatically.
Immutable audit trail across the fleet
Every model version recorded with its compute package hash and session lineage. The accountability chain required for regulated and safety-critical deployments.
Drone
Vehicle
Sensor
Base services
Powerful where it counts. Restrained where it matters.
Two deliberate boundaries: your team stays in control of what the fleet learns, and the platform sits inside your existing stack rather than replacing it.
A human confirms before the model learns.
Novel patterns are never folded into the model on their own. A person confirms first, keeping your team in control of what the fleet learns, and how fast. Meaningful human control by design, not a policy bolted on afterwards. Decisions about what to do with a detection stay with your team and your existing systems. The platform governs model improvement, nothing else.
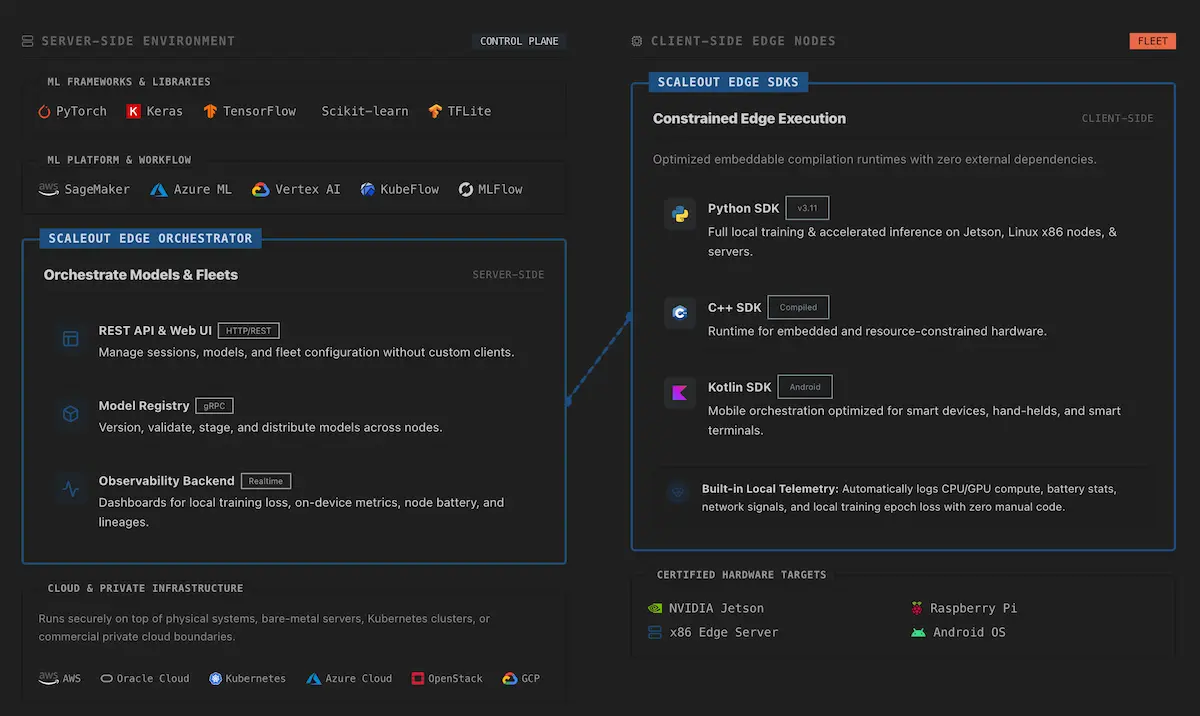
Sits between your ML environment and your edge fleet.
Scaleout Edge doesn't replace your tooling. It handles the distributed edge execution layer that your existing stack doesn't reach. Your frameworks, cloud platforms, and MLOps stay in place.
Develop centrally. Deploy and train at the edge.
Scaleout Edge sits between your existing ML environment and your edge fleet, handling the distributed execution layer that SageMaker, MLflow, and Kubeflow don't reach.
Develop centrally. Train at the edge.
Build and test models in your existing environment. Automate sessions through the REST API and Python APIClient. Export fleet telemetry via OpenTelemetry to Prometheus, Grafana, or Datadog.
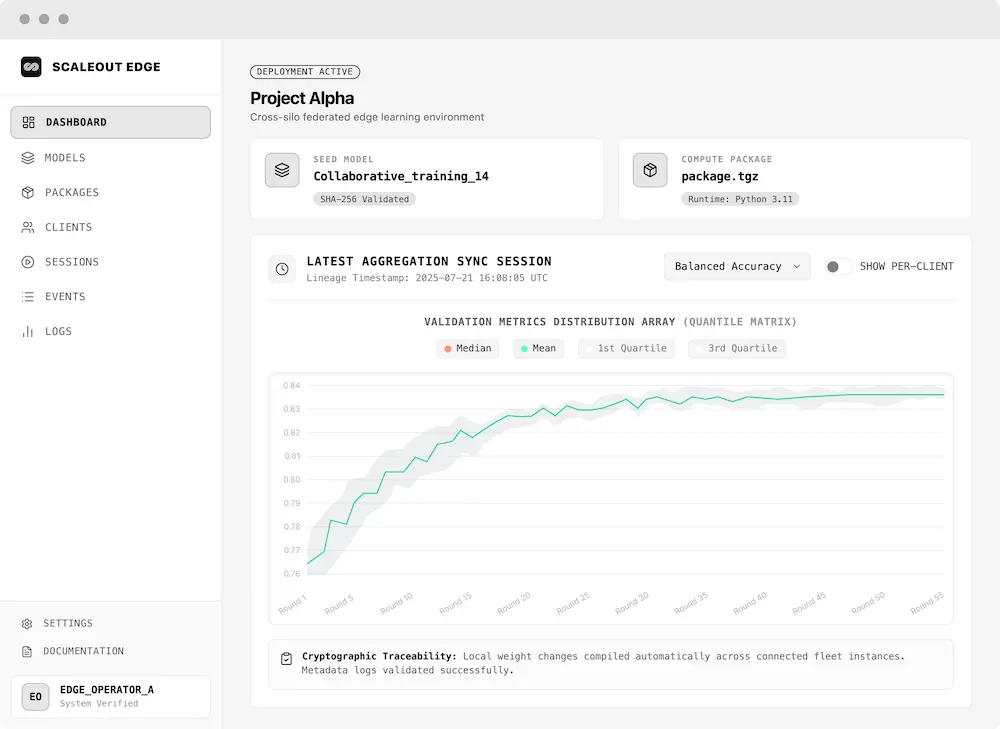
One platform. Four operational contexts.
Distributed data that cannot move and AI that must keep improving.
Autonomous Intelligence in Denied Environments
- On-device training directly on sensor streams. Intelligence at the source.
- Model updates aggregate across the swarm without raw data crossing classification boundaries.
- Node loss or signal disruption does not halt the training cycle.

One Organisation. Many Sites. Data That Can't Leave.
- Predictive maintenance trained on live sensor streams at each site. No data crosses boundaries.
- Model improvements federate across a global network of sites when connectivity allows.
- Per-site data residency met architecturally, not through access controls.
Fleet-Wide Learning Without Bottlenecks
- Safety and intrusion detection improve from each vehicle's data without exposing routes.
- Only compressed weight updates transmit, orders of magnitude less than raw telemetry.

Federated Intelligence Without Data Exchange
- Collectively train models across institutions without exposing raw data or proprietary information.
- GDPR and HIPAA compliance enforced architecturally. Data cannot leave jurisdiction.
Don't start from scratch.
Pre-built modules for the most common edge AI domains. Model architectures, training configurations, and reference workflows. Compress months of integration into days.
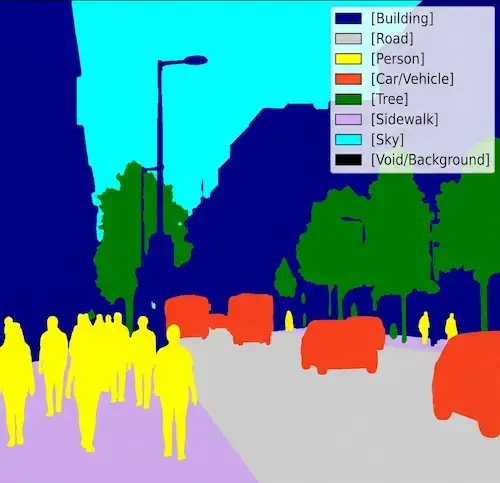
Computer Vision
Federated-ready model architectures for detection, classification, and segmentation. Supports continuous improvement of vision models across distributed fleets via federated fine-tuning. Each node learns from its local environment without sharing raw imagery.

Drone & Autonomy
Modular toolkit for unmanned vehicles. On-drone inference with offline caching and sync, autonomous flight ops for recon and engagement, and swarm coordination with ground station integration.

Speech & Language
Federated fine-tuning of speech and language models on local private data. Reference workflows for Whisper, wav2vec, and transformer-based LLMs, with edge-optimised deployment targeting hardware like NVIDIA Jetson.

Adversarial Modelling
Test whether your federated models leak private data. Privacy auditing covers model inversion, membership inference, and gradient inversion. Adversarial simulations include data poisoning, backdoor attacks, and label flipping.
Your infrastructure. Your control. Your models.
Scaleout Edge is deployed as a single-tenant instance under your control, a sovereign edge-learning capability without committing to a large, centralised programme to get it. We scope the deployment with your team, from initial pilot to production fleet.
Production deployments
Single-tenant deployment on cloud or on-prem infrastructure. Includes access to all capability modules, dedicated onboarding, and engineering support.
- Platform subscription covering the control plane, model registry, federated learning engine, and ongoing updates.
- Per-node runtime licensing for fielded systems, with volume-based tiers.
- Forward deployed engineering available and scoped separately.
Free for research
Free licenses for accredited institutions and students for non-commercial research.
- Full platform access including capability modules.
- Non-commercial use only.
How pricing works: Pricing adjusts based on deployment scope (active environments and aggregation points), node capacity (concurrent edge devices), and support tier. A natural starting point is a 60-day Stage 1 engagement to establish the lab workbench, demonstrate the full workflow, and jointly define the path to field validation.